

The Essential Of Deepseek
 Chinese AI lab DeepSeek broke into the mainstream consciousness this week after its chatbot app rose to the highest of the Apple App Store charts (and Google Play, as nicely). OpenAI’s ChatGPT chatbot or Google’s Gemini. How it works: "AutoRT leverages imaginative and prescient-language models (VLMs) for scene understanding and grounding, and additional uses large language models (LLMs) for proposing numerous and novel directions to be performed by a fleet of robots," the authors write. True, I´m responsible of mixing actual LLMs with transfer learning. China’s DeepSeek workforce have built and released DeepSeek-R1, a mannequin that makes use of reinforcement studying to train an AI system to be able to make use of test-time compute. Why this matters - in the direction of a universe embedded in an AI: Ultimately, every thing - e.v.e.r.y.t.h.i.n.g - is going to be discovered and embedded as a representation into an AI system. Those extremely large fashions are going to be very proprietary and a group of hard-gained expertise to do with managing distributed GPU clusters. The paths are clear. How labs are managing the cultural shift from quasi-educational outfits to companies that need to show a profit. Some examples of human data processing: When the authors analyze cases the place people need to course of information in a short time they get numbers like 10 bit/s (typing) and 11.8 bit/s (aggressive rubiks cube solvers), or have to memorize giant amounts of data in time competitions they get numbers like 5 bit/s (memorization challenges) and 18 bit/s (card deck).
Chinese AI lab DeepSeek broke into the mainstream consciousness this week after its chatbot app rose to the highest of the Apple App Store charts (and Google Play, as nicely). OpenAI’s ChatGPT chatbot or Google’s Gemini. How it works: "AutoRT leverages imaginative and prescient-language models (VLMs) for scene understanding and grounding, and additional uses large language models (LLMs) for proposing numerous and novel directions to be performed by a fleet of robots," the authors write. True, I´m responsible of mixing actual LLMs with transfer learning. China’s DeepSeek workforce have built and released DeepSeek-R1, a mannequin that makes use of reinforcement studying to train an AI system to be able to make use of test-time compute. Why this matters - in the direction of a universe embedded in an AI: Ultimately, every thing - e.v.e.r.y.t.h.i.n.g - is going to be discovered and embedded as a representation into an AI system. Those extremely large fashions are going to be very proprietary and a group of hard-gained expertise to do with managing distributed GPU clusters. The paths are clear. How labs are managing the cultural shift from quasi-educational outfits to companies that need to show a profit. Some examples of human data processing: When the authors analyze cases the place people need to course of information in a short time they get numbers like 10 bit/s (typing) and 11.8 bit/s (aggressive rubiks cube solvers), or have to memorize giant amounts of data in time competitions they get numbers like 5 bit/s (memorization challenges) and 18 bit/s (card deck).
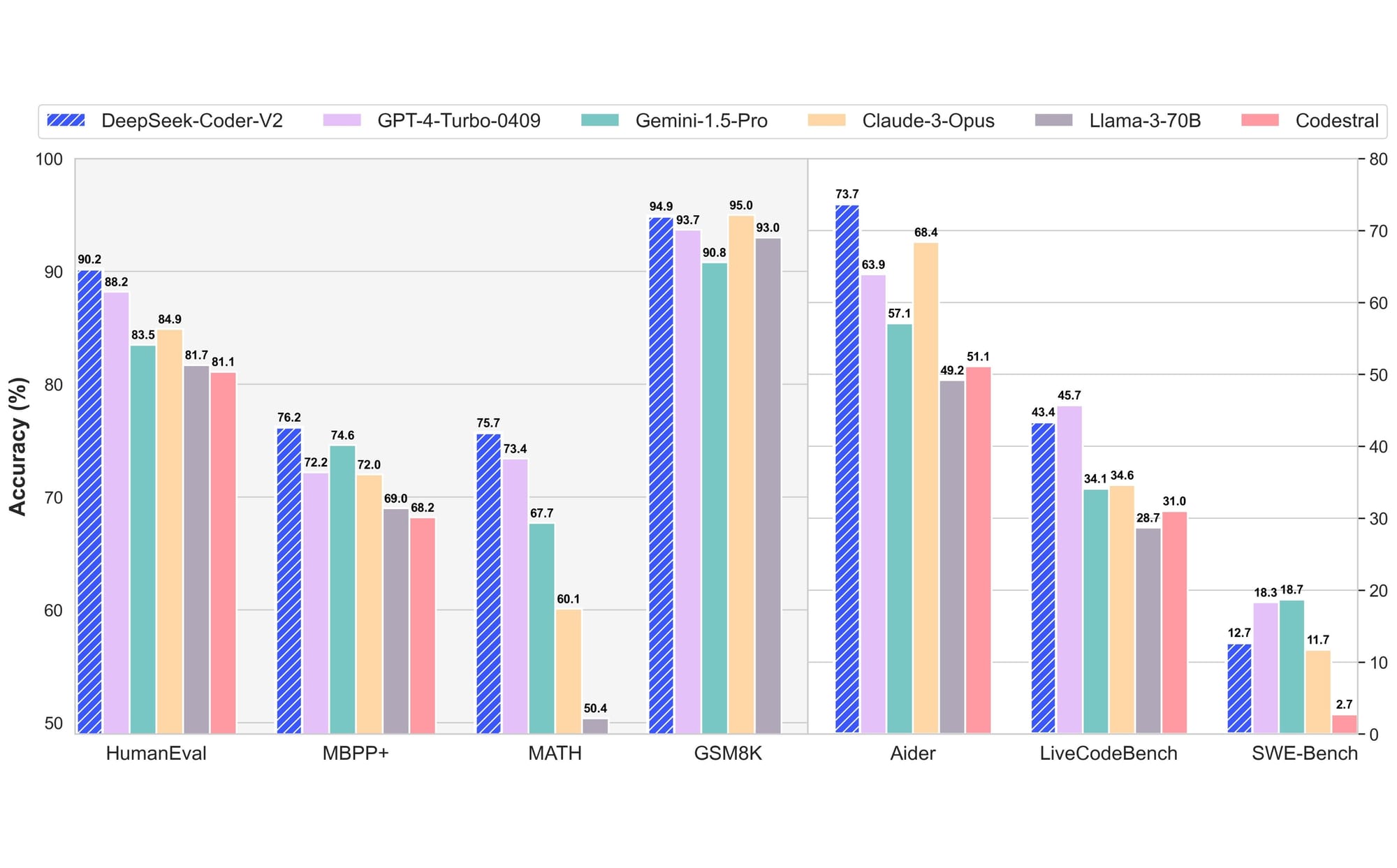
Now we'd like the Continue VS Code extension. This information, mixed with pure language and code information, is used to proceed the pre-training of the DeepSeek-Coder-Base-v1.5 7B mannequin. I’ll be sharing extra soon on find out how to interpret the steadiness of power in open weight language fashions between the U.S. This was primarily based on the long-standing assumption that the first driver for improved chip efficiency will come from making transistors smaller and packing more of them onto a single chip. Warschawski will develop positioning, messaging and a brand new website that showcases the company’s subtle intelligence providers and global intelligence expertise. 특히, DeepSeek만의 혁신적인 MoE 기법, 그리고 MLA (Multi-Head Latent Attention) 구조를 통해서 높은 성능과 효율을 동시에 잡아, 향후 주시할 만한 AI 모델 개발의 사례로 인식되고 있습니다. 이제 이 최신 모델들의 기반이 된 혁신적인 아키텍처를 한 번 살펴볼까요? AI 커뮤니티의 관심은 - 어찌보면 당연하게도 - Llama나 Mistral 같은 모델에 집중될 수 밖에 없지만, DeepSeek이라는 스타트업 자체, 이 회사의 연구 방향과 출시하는 모델의 흐름은 한 번 살펴볼 만한 중요한 대상이라고 생각합니다. 물론 허깅페이스에 올라와 있는 모델의 수가 전체적인 회사의 역량이나 모델의 수준에 대한 직접적인 지표가 될 수는 없겠지만, DeepSeek이라는 회사가 ‘무엇을 해야 하는가에 대한 어느 정도 명확한 그림을 가지고 빠르게 실험을 반복해 가면서 모델을 출시’하는구나 짐작할 수는 있습니다.
 그 이후 2024년 5월부터는 DeepSeek-V2와 DeepSeek-Coder-V2 모델의 개발, 성공적인 출시가 이어집니다. AI 학계와 업계를 선도하는 미국의 그늘에 가려 아주 큰 관심을 받지는 못하고 있는 것으로 보이지만, 분명한 것은 생성형 AI의 혁신에 중국도 강력한 연구와 스타트업 생태계를 바탕으로 그 역할을 계속해서 확대하고 있고, 특히 중국의 연구자, 개발자, 그리고 스타트업들은 ‘나름의’ 어려운 환경에도 불구하고, ‘모방하는 중국’이라는 통념에 도전하고 있다는 겁니다. 그리고 2024년 3월 말, DeepSeek는 비전 모델에 도전해서 고품질의 비전-언어 이해를 하는 모델 DeepSeek-VL을 출시했습니다. DeepSeek의 오픈소스 모델 DeepSeek-V2, 그리고 DeepSeek-Coder-V2 모델은 독자적인 ‘어텐션 메커니즘’과 ‘MoE 기법’을 개발, 활용해서 LLM의 성능을 효율적으로 향상시킨 결과물로 평가받고 있고, 특히 DeepSeek-Coder-V2는 현재 기준 가장 강력한 오픈소스 코딩 모델 중 하나로 알려져 있습니다. 역시 중국의 스타트업인 이 DeepSeek의 기술 혁신은 실리콘 밸리에서도 주목을 받고 있습니다. Moonshot AI 같은 중국의 생성형 AI 유니콘을 이전에 튜링 포스트 코리아에서도 소개한 적이 있는데요. DeepSeek 모델은 처음 2023년 하반기에 출시된 후에 빠르게 AI 커뮤니티의 많은 관심을 받으면서 유명세를 탄 편이라고 할 수 있는데요. 이렇게 한 번 고르게 높은 성능을 보이는 모델로 기반을 만들어놓은 후, 아주 빠르게 새로운 모델, 개선된 버전을 내놓기 시작했습니다. 특히 DeepSeek-V2는 더 적은 메모리를 사용하면서도 더 빠르게 정보를 처리하는 또 하나의 혁신적 기법, MLA (Multi-Head Latent Attention)을 도입했습니다.
그 이후 2024년 5월부터는 DeepSeek-V2와 DeepSeek-Coder-V2 모델의 개발, 성공적인 출시가 이어집니다. AI 학계와 업계를 선도하는 미국의 그늘에 가려 아주 큰 관심을 받지는 못하고 있는 것으로 보이지만, 분명한 것은 생성형 AI의 혁신에 중국도 강력한 연구와 스타트업 생태계를 바탕으로 그 역할을 계속해서 확대하고 있고, 특히 중국의 연구자, 개발자, 그리고 스타트업들은 ‘나름의’ 어려운 환경에도 불구하고, ‘모방하는 중국’이라는 통념에 도전하고 있다는 겁니다. 그리고 2024년 3월 말, DeepSeek는 비전 모델에 도전해서 고품질의 비전-언어 이해를 하는 모델 DeepSeek-VL을 출시했습니다. DeepSeek의 오픈소스 모델 DeepSeek-V2, 그리고 DeepSeek-Coder-V2 모델은 독자적인 ‘어텐션 메커니즘’과 ‘MoE 기법’을 개발, 활용해서 LLM의 성능을 효율적으로 향상시킨 결과물로 평가받고 있고, 특히 DeepSeek-Coder-V2는 현재 기준 가장 강력한 오픈소스 코딩 모델 중 하나로 알려져 있습니다. 역시 중국의 스타트업인 이 DeepSeek의 기술 혁신은 실리콘 밸리에서도 주목을 받고 있습니다. Moonshot AI 같은 중국의 생성형 AI 유니콘을 이전에 튜링 포스트 코리아에서도 소개한 적이 있는데요. DeepSeek 모델은 처음 2023년 하반기에 출시된 후에 빠르게 AI 커뮤니티의 많은 관심을 받으면서 유명세를 탄 편이라고 할 수 있는데요. 이렇게 한 번 고르게 높은 성능을 보이는 모델로 기반을 만들어놓은 후, 아주 빠르게 새로운 모델, 개선된 버전을 내놓기 시작했습니다. 특히 DeepSeek-V2는 더 적은 메모리를 사용하면서도 더 빠르게 정보를 처리하는 또 하나의 혁신적 기법, MLA (Multi-Head Latent Attention)을 도입했습니다.
대부분의 오픈소스 비전-언어 모델이 ‘Instruction Tuning’에 집중하는 것과 달리, 시각-언어데이터를 활용해서 Pretraining (사전 훈련)에 더 많은 자원을 투입하고, 고해상도/저해상도 이미지를 처리하는 두 개의 비전 인코더를 사용하는 하이브리드 비전 인코더 (Hybrid Vision Encoder) 구조를 도입해서 성능과 효율성의 차별화를 꾀했습니다. 불과 두 달 만에, DeepSeek는 뭔가 새롭고 흥미로운 것을 들고 나오게 됩니다: 바로 2024년 1월, 고도화된 MoE (Mixture-of-Experts) 아키텍처를 앞세운 DeepSeekMoE와, 새로운 버전의 코딩 모델인 DeepSeek-Coder-v1.5 등 더욱 발전되었을 뿐 아니라 매우 효율적인 모델을 개발, 공개한 겁니다. 두 모델 모두 DeepSeekMoE에서 시도했던, DeepSeek만의 업그레이드된 MoE 방식을 기반으로 구축되었는데요. DeepSeek 모델 패밀리의 면면을 한 번 살펴볼까요? 다시 DeepSeek 이야기로 돌아와서, DeepSeek 모델은 그 성능도 우수하지만 ‘가격도 상당히 저렴’한 편인, 꼭 한 번 살펴봐야 할 모델 중의 하나인데요. 거의 한 달에 한 번 꼴로 새로운 모델 아니면 메이저 업그레이드를 출시한 셈이니, 정말 놀라운 속도라고 할 수 있습니다. free deepseek 모델 패밀리는, 특히 오픈소스 기반의 LLM 분야의 관점에서 흥미로운 사례라고 할 수 있습니다. 특히 DeepSeek-Coder-V2 모델은 코딩 분야에서 최고의 성능과 비용 경쟁력으로 개발자들의 주목을 받고 있습니다.
Reviews